- This topic has 15 replies, 12 voices, and was last updated 11 years ago by .
Viewing 16 posts - 1 through 16 (of 16 total)
-
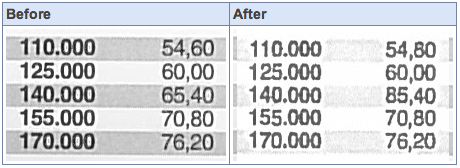
When is a photocopy not a photocopy?
-



Viewing 16 posts - 1 through 16 (of 16 total)
The topic ‘When is a photocopy not a photocopy?’ is closed to new replies.