Forum menu
My guide to writing good software:
1. KISS. Being stupid is actually an advantage to a computer programmer. Up to a point.
2. Two mutexes good, four mutexes bad.
3. C++. Just say no.
4. std::shared_ptr<>. See item 3. No, it does *not* prevent memory errors or leaks, it just makes them harder to figure out.
5. If it hasn't been tested, it doesn't work.
std::shared
This doesn't sound like the way to win friends.
6. Testing means verifying that the things that shouldn't happen don't, not just that the things that should happen do.
3a. Java. Just say no.
7. There must be a better way (not my words, I stole them from one of the Python Devs that does a lot of software training)
Understand the user needs
Understand the user needs
Understand the user needs
Build the smallest thing possible
8. Profile first, [b]then[/b] optimize. Don't just do the cool thing you've fancied doing for ages.
9. Contribute back. Whether is is code in an open source project or documentation or other things doesn’t matter. But contribute. It makes you a better dev
Rachel
I refer to the Klingon Programmers Manual which is very short.
Documentation is for the weak and timid.
10. Stack Overflow + Google 😉
Until someone else has used it, it doesn't work
Understand the user needs
+1
As an example of 'Clever Design vs User Experience':
[img]  [/img]
[/img]
1. Best not done on Friday afternoon after the lunchtime beers. Makes the coding sail along, but the debugging on Monday is another matter entirely.
2. Googling about R is difficult, until you learn to add "project" to the search terms.
3. A sufficiently talented coder can write fortran in any language.
11. Write decent comments! Tell me why a line of code exists, not what it does - I can see that by looking at it!
12. Don't code when your brain is toffee, surf STW instead, it'll save you uncoding everything later.
13. Imagine reading the code you've written at 03:00, after being dragged out of your bed for a call out. Can you still understand what it's doing?
Disagree with 3 by the way. Nowt wrong with well written C++.
FWIW, I'm currently working on legacy safety-critical medical software controlling delivery of radiation and it uses a mixed bag of C, C++, C# and... Visual Basic! 😯
sounds like something that I designed 🙂FWIW, I'm currently working on legacy safety-critical medical software controlling delivery of radiation and it uses a mixed bag of C, C++, C# and... Visual Basic!
That's quite disturbing. C# and VB require windows, and i'd never trust anything safety critical to run on windows - it has far too much of a mind of its own.FWIW, I'm currently working on legacy safety-critical medical software controlling delivery of radiation and it uses a mixed bag of C, C++, C# and... Visual Basic!
9. Contribute back.
Work don't let me and these days I have very little inkling to do even more coding in my spare time.
9. Contribute back.Work don't let me and these days I have very little inkling to do even more coding in my spare time.
You learn an awful lot if you do though. You'll find a few tiny contributions from me inside git, it's well worth it.
EDIT: which reminds me: code is read far more times than it is written.
That's quite disturbing. C# and VB require windows
Can't say too much for obvious reasons, but yes it does involve Windows Embedded Standard (i.e. restricted version of XP) but the real-time stuff is handled on LynxOS.
Disagree with 3 by the way. Nowt wrong with well written C++.
Is there an existence proof for this?
A friend went to a lecture by Bjarne Stroustrup, where BJ talked at length about the kinds of problems people were having with the terrible code people were writing, and what was being done in the language to make this better.
At the end, he asked for questions. My friend said, "you've given us lots of examples of C++ projects with badly written code, can you give us an example of a well written one?".
There was a long pause. And then the great man replied, "No".
There are no well written C++ programs in existence.
I'm pretty sure no one intentionally writes bad code, it just happens as a product of circumstances...
Is there an existence proof for this?
Well I do a lot of work in embedded software. The options there are basically assembly, C or C++.
And even then it is often a restricted subset of C++ (e.g. no heap allocation allowed!)
But you are surrounded by embedded software that generally works very well.
Don't work for Equifax do you. GrahamS? 😉
Rachel
1. Best not done on Friday afternoon after the lunchtime beers.
Does this still happen? I remember the guy who effectively ran the network for a government department being useless after lunch, and I also remember the look of bewilderment when the US company that got the outsourcing contract heard there was a bar on site.
Don't work for Equifax do you. GrahamS?
Hey, it worked on my machine.
I also remember the look of bewilderment when the US company that got the outsourcing contract heard there was a bar on site
Once, when working on the (surprisingly complex) embedded software for a car door, we went over to the plant in northern Spain to work with the engineers there.
All kinds of machines assembling car parts, as well as other machines testing them (robots opening and closing doors, sitting on seats etc, just like the adverts only much dirtier).
Their "software department" was literally 3 guys in a corner of the plant, writing code and backing it up to zip files in "My Documents". No source control. No build servers. DevOps didn't really exist in those heady days.
Anyways, on the factory floor they had vending machines full of beer, and the two hour lunch break involved a three course meal and a carafe of wine!
Happy days.
Having had all my R&D move to India and China, I'm wondering if this page can be translated into Hindi and Mandarin 🙄
1: "Build things people want"
The rest is quite frankly trivial details if you've got this bit right.
In my experience mrblobby, you'll get five folk on an Indian team. One will speak good enough English to be the "project lead" and will say yes to absolutely everything even if they have no idea what you mean. One will actually know what they are doing and do all the real work. And the other three will be getting some on-the-job training from the one that knows what they are doing.
As with all outsourcing, managing it with your own tests, quality reviews, milestones etc is the key. Sadly most companies seem to think they can just push it out the door and forget about it.
1: "Build things people want"
[img]  [/img]
[/img]
The hard part is to give them what they need, [i]not[/i] what they say they want.
[img]  [/img]
[/img]
Documentation is for the weak and timid.
14. (or whatever number we're up to now) The code, by definition, documents exactly what it does and how it works, more accurately than any other written documentation.
The code, by definition, documents exactly what it does and how it works, more accurately than any other written documentation.
But it doesn't tell you WHY
Good documentation is [I]hard[/I]
Rachel
The hard part is to give them what they need, not what they say they want.
Absolutely, which is exactly what I've made a career out of. (UX Designer)
Never let Sales decide the features based on what they think the customer wants or what they personally want to be able to get that sale commission.
End user documentation - no-one RTFMs, don't bother. UI should be self explanatory. If not, invest in support. Even with comprehensive documentation, they'll still ring support first.
mrblobby - Member
Having had all my R&D move to India and China, I'm wondering if this page can be translated into Hindi and Mandarin
Copy all this and paste it onto Stack Overflow. It's where they'll be looking anyway 😉
As a lead developer looking after a team of contractors, I generally didn't put rules onto my staff - just once principle -
Your goal should be to write readable, maintainable and efficient code.
If you don't do that and I spot it in a code review, you're doing it again.
Also, it's twice as hard to debug code as it is to write it, so don't be as clever as you can be when you write code as you'll need a genius to debug it...
9. Contribute back.
Work don't let me and these days I have very little inkling to do even more coding in my spare time.
If you use open source software in any meaningful way, and scratch an itch by fixing spelling in the manual, or fixing a small bug, or implementing a new feature, then there are generally ways to convince work to let you.
One option is to not mention the company at all (loads of contributions in projects I work on come from China in Chinese working hours via @gmail.com), or the worst case of Legal+CTO vetting each project you submit to. Either way, aside from not having patches locally which can be a pain on upgrades, contributing back to an open project means you build up a relationship with the developers, so when you *need* help they're more willing to help.
We have made it so that when helping patch Drupal code, you can declare any employer and client you want as “supporting” the time needed to do the work. Then, that gets added up and used to push that employers profile higher on the Drupal marketplace section of the website.
It’s a very neat system.
Rachel
there are generally ways to convince work to let you.
I am a full-time employee to a company that essentially contracts us out to other companies. Any work off the clock or that could be construed as threatening privacy of a client would be very frowned upon.
Even stuff like StackOverflow questions have to be [i]very[/i] careful.
If a client tells me to contribute to open-source I gladly will, but otherwise, not a chance.
Ugh documentation... don't even get me started on technical documentation being written and interpreted by Indians and Chinese in second/third language English 🙁
oldnpastit - Member
1. KISS. Being stupid is actually an advantage to a computer programmer. Up to a point.
This is important. Don't be clever if you can be simple. Clever is a complete pain to debug and/or maintain. If you have to be clever please document your cleverness in a way that seems like you're explaining it to a moron. Because if you have to fix it in 6 months or a year or even later you'll be feeling like a moron as you scratch your head over the convoluted code your younger, stupider self thought was clever.
This is important. Don't be clever if you can be simple. Clever is a complete pain to debug and/or maintain. If you have to be clever please document your cleverness in a way that seems like you're explaining it to a moron. Because if you have to fix it in 6 months or a year or even later you'll be feeling like a moron as you scratch your head over the convoluted code your younger, stupider self thought was clever.
In addition, it turns out you can't add developers to your project, because your new developers just won't be able to figure out what the blazes you are/were trying to do. Especially if it's anything involving complicated lifetimes and std::shared_ptr<>.
Or so I've heard anyway.
What have you got against std::shared_ptr<> oldnpastit?
Work pretty well in my experience. Certainly a lot less error prone than managing raw pointers . The only real issue I've had is with programmers who are still trying to write in C and just don't understand them.
Bit like in C# world, rewriting everything as LINQ expressions, because it's cool. Actually I fell for that a bit, but ReSharper didn't help as it kept advising this or that could be rewritten in one cool LINQ statement. Looking back at the code and especially if it's someone who doesn't know LINQ and got no idea what's going on there.
Has its place though. A nice bit of LINQ vs some hideous big loop and conditional checks.
There's the opposite end where a team lead or project manager decides to ban the cool stuff because basically they don't understand it, so you're stuck on legacy stuff and have frustrated developers.
I am a full-time employee to a company that essentially contracts us out to other companies. Any work off the clock or that could be construed as threatening privacy of a client would be very frowned upon.
My old job was with a small consultancy. We preached the open source way and the contracts said that where possible code would be freely licensed and public, if the client wanted proprietary code the rates were higher...
Worked surprisingly well!
What have you got against std::shared_ptr<> oldnpastit?Work pretty well in my experience. Certainly a lot less error prone than managing raw pointers . The only real issue I've had is with programmers who are still trying to write in C and just don't understand them.
They are slow - there's an extra load of locking/unlocking that goes on in the background. Usually that's OK, but sometimes it can cause weird slowdowns.
Worse than that is it encourages program design that doesn't think up-front about how lifetimes and ownership will work.
It also goes horribly wrong if people take the raw pointer out of a std::shared_ptr<> and then stuff it into another, unrelated shared or unique ptr. While you might think that people shouldn't do this (and you would be right) it turns out that they do.
Also they look really ugly.
They are slow
Slower, yeah, but [i]slow[/i]? As in measurably so? Not IME. Not unless you are absolute hammering them with billions of objects. (And if you are sharing billions of objects then your code is.. interesting).
Bear in mind that if you [i]don't[/i] use them then you may need to roll your own thread-safe code to manage the lifetime of raw pointers to dynamically allocated resources. That's not easy! It often ends up with [i]more[/i] overhead than shared_ptr. Plus it's a major source of bugs.
Worse than that is it encourages program design that doesn't think up-front about how lifetimes and ownership will work.
Lifetimes and ownership don't matter though - that's the point. A shared object has shared ownership and lives as long as at least one owner still cares. That's perfect.
In contrast smart pointers [i]force[/i] people to make up-front design decisions about whether an object should be unique, shared or weak - something you can't even express with raw pointers.
e.g. if a public method returns a raw pointer then I need to go trawl the source to figure out if I need to delete it or not (and also [i]how[/i] to delete it). If that method changes those ownership semantics later, then it can impact my code without me even noticing.
But if the method returns a smart pointer then I know exactly where I am and any later changes to that design are explicit in the signature.
It also goes horribly wrong if people take the raw pointer out of a std::shared_ptr<> and then stuff it into another, unrelated shared or unique ptr. While you might think that people shouldn't do this (and you would be right) it turns out that they do.
Yep true. Those people are C programmers pretending to write C++. 🙂 That should be caught at peer review.
But likewise there are a hundred and one ways to get raw pointers horribly wrong and many of them are very hard to catch.
In [url= https://www.safaribooksonline.com/library/view/effective-modern-c/9781491908419/ch04.html ]"Effective Modern C++"[/url] Meyers say:
...we might try to enumerate the reasons why a raw pointer is hard to love:1. Its declaration doesn’t indicate whether it points to a single object or to an array.
2. Its declaration reveals nothing about whether you should destroy what it points to when you’re done using it, i.e., if the pointer owns the thing it points to.
3. If you determine that you should destroy what the pointer points to, there’s no way to tell how. Should you use delete, or is there a different destruction mechanism (e.g., a dedicated destruction function the pointer should be passed to)?
4. If you manage to find out that delete is the way to go, Reason 1 means it may not be possible to know whether to use the single-object form (“delete”) or the array form (“delete []”). If you use the wrong form, results are undefined.
5. Assuming you ascertain that the pointer owns what it points to and you discover how to destroy it, it’s difficult to ensure that you perform the destruction exactly once along every path in your code (including those due to exceptions). Missing a path leads to resource leaks, and doing the destruction more than once leads to undefined behavior.
6. There’s typically no way to tell if the pointer dangles, i.e., points to memory that no longer holds the object the pointer is supposed to point to. Dangling pointers arise when objects are destroyed while pointers still point to them.
Raw pointers are powerful tools, to be sure, but decades of experience have demonstrated that with only the slightest lapse in concentration or discipline, these tools can turn on their ostensible masters.
(Very good book by the way)
Also they look really ugly.
I'll give you that one too. But C++ rarely an elegant looking language. 😆
I am primarily a C programmer. While C's raw pointers can be the source of a lot of trouble it is at least nice to think that I don't have to understand quite as many different ways to handle pointers (and therefore how to handle each sort of pointer safley) as I would in C++.
C raw pointers are a [i]bit[/i] easier compared to C++ raw pointers, but there is a good reason why various safety standards (e.g. MISRA C) completely ban the use of dynamically allocated memory.
Experience shows it is just too dangerous.
My limited exposure to MISRA suggests that it's a right old barrel of laughs.
One friend had some sort of connection to a group that contributed to MISRA or something similar. His impression was that the people assigned to work on it were put there to keep them from doing the harm they'd inflict if assigned to real software projects.
It's a pretty tough standard - but it's also the reason your car doesn't randomly stop because it has run out of memory 😀
It's easy to work around MISRA - write it in assembler instead.
If you can't do it in assembler, you probably have an over-complex design.
Or, y'know, just stick to statically allocated memory.
If you can't do it in assembler, you probably have an over-complex design.
Surely if you can't do it in assembler, then neither can the compiler? Unless commercial compilers have secret access to the hidden / undocumented processor features, and you're doing something weird and very low level (that probably needs C with inline assembler anyway) ?
One of the things I like about some of the unit test frameworks is that I can structure my tests into a series of assertions, or even use case descriptions, of how my software components work.
That, in conjunction with good naming and good software partitioning into focused libraries/dlls, can provide good 'living' documentation for the system that someone can be sure is still relevant, unlike technical documentation produced at the start of a project.
We're using Mocha at the moment for unit up to end-to-end tests and the descriptions are structured to provide even nicer documentation.
Even writing embedded stuff we rarely go down to assembler, except for the really really low-level hardware interface stuff where you need to get clock cycle timing perfect.
[img]  ?oh=c5f826b7a51867baeb73bf31bb50da15&oe=5A413E77[/img]
?oh=c5f826b7a51867baeb73bf31bb50da15&oe=5A413E77[/img]
1. You can't write your own crypto. You might think you can but you can't, so save your users a lot of trouble and use the platform crypto instead. And make it easy to upgrade.
2. Parsing XML is difficult, so use the platform XML parser. It will save you so much trouble in the future.
3. When you are ripping off Open Source components, credit the teams that wrote it and make their code easy to upgrade.
4. Leave your ego behind. It might be code you have spent hours, days or weeks on, but that should not stop you from accepting that it may have bugs. The last thing a project needs is someone getting defensive and not fixing problems.
5. Architect and design the system defensively. There will be security vulnerabilities in your code, so if the whole system is geared up to defend agains them, it will be less painful to fix.
[code]"1" + 1 == 0
'1' + 1 == '2'
'1' + '1' == 'b'[/code]
Damn C 😀
I like c++ but working as a 3ds max developer have to put up with shit like this on a daily basis 😀
BOOL ShapePickMode::HitTest(IObjParam *ip, HWND hWnd, ViewExp *vpt, IPoint2 m,int flags) {
if (!mpEditPoly) return false;
if (!ip) return false;
return ip->PickNode(hWnd,m,this) ? TRUE : FALSE;
}
this is relatively mild rubbish from the sdk I just happen to have open when reading this thread
Klunk: Mmmmm....
Poorly named parameters? Check.
Unused parameters? Check.
Hiding errors as valid return values? Check.
Passing pointers when they should probably be references? Check.
Not using const? Check.
Not using the built in true/false constants? Check.
All good stuff. To be fair though, you can write a crap API in just about any language.
The golden rule of writing good software is "look at how Garmin have done it then do the exact opposite".
Or, y'know, just stick to statically allocated memory.
I do, I do. My current gig is genuinely easier in assembler.
Anybody else waiting eagerly to see what molgrips has to say ? 🙂
My current gig is genuinely easier in assembler.
Blimey, that's rare these days.
We tend to design in a C/C++ interface layer on top of any assembler stuff. That way we can build the suitable Mocks/Fakes/Stubs/Spies for unit testing purposes against that interface without necessarily needing them to run on the target hardware.
Still do most of my work in assembly as well (low power DSP/comms stuff). Except for the actual assembler for the DSP we use, which I wrote myself in nice clean portable C 🙂
And since unbelieveably no-one's posted it yet, here's the [url= https://xkcd.com/844/ ]obligatory XKCD[/url] ...
[img] 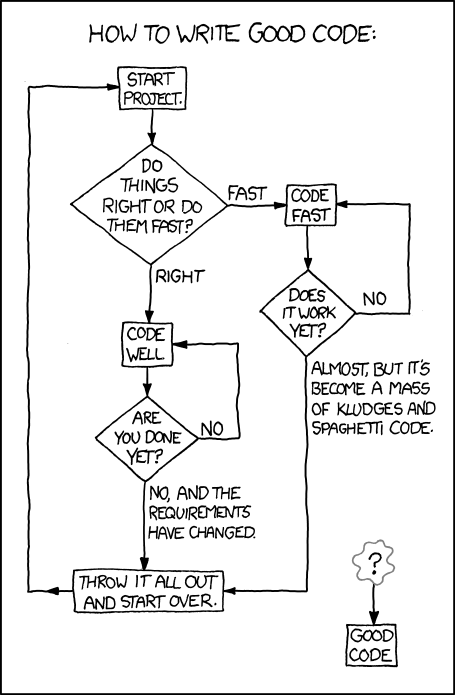 [/img]
[/img]
Definitely the engineering rule of "pick two" applies for software -
- cheap (quickly written)
- light/fast (performance)
- strong (robust/reliable)
I had the misfortune to try and maintain a colleague's piece of code, I think it was a TIFF manipulation routine. C. I swear to god there was *a* routine, and best part of 3,000 lines of code. I may have wept.
10. When you find yourself writing stuff "just in case" or for future upgrades, be very wary!
Anybody else waiting eagerly to see what molgrips has to say ?
I'm not reading this thread.
[code]Exception in molgrips.cpp: molgrips not found.[/code]
2. Two mutexes good, four mutexes bad.
2. Two mutexes good, four mutexes bad. [b]No mutexes best[/b].
here are some more .......
Adding extra unwanted stuff because they think it might be needed later
Not refactoring
Editor inheritance
Not handling the unexpected
Saying they are complete when what they actually mean is 'I've nearly done typing it in and I think it will compile'
Surely just create a mock/fake/stub molgrips and have it say whatever you like?
Because molgrips is written in Java.
So first we'll need an AbstractMolgrips class produced by an AbstractMolgripsFactory, realised by a RealMolgripsFactory and MockMolgripsFactory then we'll want an AbstractMolgripsFactoryFramework to take care of selecting the factory... ...and probably some Beans too for good measure... 😉
SELECT name
FROM stwers
WHERE bighitter = TRUE
AND currently_flouncing = FALSE
AND unwilling_mac_user = TRUE
;
Or something. I don't do this for an actual living, which is probably for the best where our codebase is concerned.
We tend to design in a C/C++ interface layer on top of any assembler stuff.
I've worked on a project with a C/C++ interface layer underneath the assembler stuff.
That was slightly leftfield.
Yeah, that's an erm... [i]unusual[/i] design decision 😕
'1' + '1' == 'b'
What the shit is this?
What the shit is this?
In C the char type is an integer type (usually a 8 bits) and it just holds the [url= https://en.wikipedia.org/wiki/ASCII ]ASCII value[/url] of the character.
So
[code]'1' + '1' == 'b'[/code]
works because it is equivalent to
[code]49 + 49 == 98[/code]
😀
Can you figure out the other two though?
[code]"1" + 1 == 0
'1' + 1 == '2'[/code]
Ok, so '1' + 1 == '2' is essentially the same - you're incrementing the ASCII value?
"1" + 1 == 0 - is that just a type mismatch, adding an integer to a string? Sounds like a tenuous explanation but...?
I should add, I've never touched C++ in my life. Beyond Pascal at Uni I've only really dabbled. Despite that I was actually employed as a programmer at one point, but that was glorified web dev building an intranet system. HTML pages with client-side Javascript and server-side VBscript, often with all three on the same line of code. Fun times.
"Well, actually"
I see what the point is: "1" is a pointer to an array of characters, specifically two characters '1' (ascii 49) and '<turns out its impossible to write backslash-zero here>' (ascii 0, the null byte). Adding to an array is moving the pointer, so the pointer now points at the null byte.
But if you put that into a compiler then that isn't what it would say...
const char *s = "1";
puts(s); // prints '1'
puts(s+1) // prints a blank line