Forum menu
**** knows but hopefully. I'm sure the MHRA are beavering away behind the scenes - and they may even act in a unilateral fashion when it comes to mutual recognition in the short term.
Bwahahahaha! In my experience the two agencies take pride in being independent. Sometimes fiercely independent! My experience includes sitting in front of them arguing btw.
So does mine.
My main job is cleaning up the mess before and after the MHRA/FDA have visited. I'll question some ex-MHRA NSF guys I know on it if I get the chance though.
UK vaccine approval is by either the EMA, referred to in article, or MHRA.
Yes, I know FDA approval is not applicable to UK but EMA is - for now.
I didn't expect 100/100.
It seems to me that the EMA 50% efficacy threshold reflects the pressure to develop a vaccine; it's much better than nothing but that relatively low bar combined with a less than universal take-up is...concerning - to me.
Also worth noting that real world effectiveness is likely to be lower than efficacy.
Would be interested in TiRed's views.
combined with a less than universal take-up is…concerning – to me.
If I had my way the vast majority of the population would be getting it whilst sitting/kneeling at the bangy end of a gun.
I’ll come back in a few days to remind you that you talked of a “daily spike” TiRed 🙂
Scratch that "few days"
All approvals for new devices, medicines and vaccines are based on benefit-risk arguments. They will vary for each application. Being first with a less efficacious vaccine may still be reasons to grant either an EUA (Emergency Use Application - more data coming...) or an approval. Approvals may come with "post-marketing commitment (you can sell it but we want more data). I've had blatant disagreements based on the same data. If I am blunt (i.e., my personal opinion) the FDA is a pretty sound professional review organization, whereas the EMA is a group of project managers who cat-herd academics into making opinions.
There is no substitute for numbers and duration of subjects studied. So the applications may be EUA (we have some data!) with longer follow-up. The EUA can be rescinded if the data does not stack up. In oncology this is known as "Conditional approval". I don't think there has been such a scheme for vaccines - they work or not and you have 1000's of subject-years of data.
In my experience, being first with any new treatments other than an antibody therapy, has tended not to be the most successful path. I suspect a SARS-COV2 vaccine may be the same. Fastest to market was based on speed to make a candidate. And novel technologies can make a candidate for testing faster. Proven technologies may be more effective. We shall see.
[tl:dr] New treatments and vaccines can be approved by regulators based on early data if the apparent benefits outweigh the risks. But this may be conditional on collecting more data and taken away if it doesn't ultimately work. First may not be best.
@TheCaptain, could you elaborate. I'm vaguely aware that you and TiRed have differences of opinion but I dip in and out of this thread and I'm far to lazy/busy to go back and read 20 pages of context.
The EMA/FDA MRA currently only relates to GMP (manufacturing) inspections. It doesn't cover vaccines (yet) either.
MRA are generally born out of trade agreements. So don't expect the MHRA/FDA to have mutual recognition of anything anytime soon.
Scratch that “few days”
Still a bit uppy? What's the rolling 7-day average? Admissions is well-predicted at about 850-1000 per day. I modelled them both simultaneously, but prediction from admissions is ok too using the formula I posted previously.
oakley - that would also be my approach...you're getting this jab whether you want to or not.
If I am blunt (i.e., my personal opinion) the FDA is a pretty sound professional review organization, whereas the EMA is a group of project managers who cat-herd academics into making opinions.
The FDA have said things that have raised my eyebrows in the past. The EMA's role as cat-herders however, is a function of the fact that it is another layer over national regulatory bodies. They do a lot of good work and do some things better than the FDA.
Fastest to market was based on speed to make a candidate. And novel technologies can make a candidate for testing faster. Proven technologies may be more effective. We shall see.
Fastest to market can be a loss leader, you have also then developed expertise in a field before anyone else. It's been five years since Amgens Imlygic went to market, meanwhile no one else has managed to get a comparable product to market on developed the same level of expertise that product required.
The EMA/FDA MRA currently only relates to GMP (manufacturing) inspections. It doesn’t cover vaccines (yet) either.
It allows you to wave batch testing on imports as well, also there are new facilities being built both in the EU and the states to scale up vaccine production.
So it could speed things up a little.
Products covered
human biologicals, including vaccines, immunologicals and biotherapeutics
So it still helps speed things up a little.
Well no, vaccine manufacture is not due to be added until 2022.
Really, states on the EMA site that vaccines are included?
Ooooh the yanks aren't reciprocal at the moment on vaccines. Learn something new everyday.
Imlygic sales were projected to be $200M/year. That's less than a week's sales for pembrolizumab (anti-PD1), and there are four other PD-1s in the same class! It wasn't for being first that Imlygic sales haven't taken off 😉 . It's an interesting concept though.
But in vaccine space, it's going to be capacity rather than competition I expect.
HAH and the EMA have removed the UK from the MRA page.
Awesome.
We're all ****ing doomed.
Included in original proposed scope, decision not due to be made until 2022
It wasn’t for being first that Imlygic sales haven’t taken off 😉 .
Mostly because they only ever bothered when I was there trying to get it approved for late stage patients who are going to die shortly anyway, for reasons that I have forgotten.
Daily cases now higher than the total number of posts on this thread. 🙂
@oakleymuppet , I'm interested in exploring the difference between a somewhat arbitrary curve fit (which I hope @TiRed won't mind me characterising his method as) and my approach of fitting a simple epidemiological model. In essence I'm also fitting a curve, but the shape (family) of curves that I'm using are based on fundamental albeit simplified epidemiological dynamics which I think is likely to be better than just choosing a shape that looks roughly right. Especially when you extrapolate into the future.
Specifically, I believe his graph on p455 is far too optimistic. Sadly.
I may be misrepresenting TiRed's approach somewhat in which case he may well respond...
What curve are you using, I'm mildly statistically literate (I was achieving firsts in undergraduate level statistics). I do say mildly because I cut my studying short during Covid to help save the world (mostly because I want to go to actual lectures and life was getting in the way, but saving the world sounds better as an excuse in interviews). If you could humour me with further detail on the differences between your approaches, I'd be very interested.
To a first order approximation, ie where there is little or no immunity, the methods are the same (it’s just that an exponential polynomial is easier to fit than a differential equation model - I fit those too btw). There are multiple data streams. I use the daily admissions data and the death within 28d by date of death. The statistical approach makes fewer assumptions but one reduces to the other with a chosen parameter set.
People are admitted to hospital with a periodicity. They tend to die on any day of the week. Early in the epidemic only reported deaths on a day was collated manually. Now date of death is also reported so you don’t see the big peaks and troughs due to reporting delays. The media eventually started to report 7d rolling means to remove the periodic effects.
I'm using a fairly standard numerical model of the SEIR type which describes the progress of a disease through a population (assumed to be a mass of identical people, no accounting for different age groups etc). In reality it's not much more than a (local in time) exponential curve but it has appropriate time lags and smoothings between changes in R parameter (the main free parameter in the model), infections, case detection, and deaths. Although the model itself is simpler than (and in many ways inferior to) those used by the likes of SAGE, this brings the advantage that I can fit the parameters to the available data using fairly advanced techniques that they don't seem to know (or care) much about. Some groups like bsu are doing similar work but they aren't quite as good as me at it:
https://www.mrc-bsu.cam.ac.uk/now-casting/
The media eventually started to report 7d rolling means to remove the periodic effects.
But that also lags. We’re acting too late, again, partly due to paying too much attention to “old” data.
Rest assured kelvin, I use daily admissions data from up to the day before. The death data for the current week isnt included in the model. The lag is 7 days from admissions to deaths, so one has a week of future.
As for SEIR models, the simple ones are sufficient to describe national level just fine. The big question is;
Is the turnover in cases/admissions/deaths due to reduced contacts or increased proportion immune?
Various parameter combinations can give an apparently similar conclusion. One Nobel prize winner believes the latter, having discovered the Gompertz equation and Tcell cross reactivity. The simple SEIR model, monitoring R for seropositives does not support that view.
Then there is the timings and what R does After such changes. We’ve had five changes since March 23.
That article from thecaptain is suggesting a daily infection rate of 53k and doubling in ten days whereas the government's saying 26k daily positive tests. Given the effectiveness of track and trace, that's a rather disturbing disparity.
"the advantage that I can fit the parameters to the available data using fairly advanced techniques that they don’t seem to know (or care) much about"
Go on, I'm interested - For SEIR models, I use random space sampling with an optimization based on an assessment of RMSE as a measure of fit. Then simulate accordingly with parameter uncertainty and estimate median and prediction intervals from 10,000 samples. Many others use likelihood methods, better ones assume Poisson or negative binomial likelihoods.
Timing of interventions, their magnitude and speed of onset, is more challenging than age- and regional structural aspects. Here's one example with the older Deaths data. I have a simple model with changes in R taking some time to take hold. IFR, R and incubation period are all nuisance parameters with correlations:
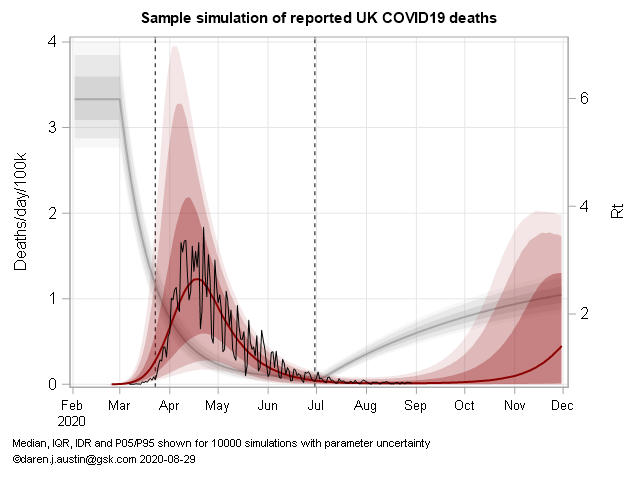
@TiRed, my approach is fundamentally based on the standard Bayesian updating paradigm with likelihood based on model fit (which is pretty much equivalent to minimising RMSE in log space). The particular novelty of my work is that my iterative Kalman smoother is very efficient in high dimensional applications meaning I can fit a model which has daily increments on the R value (ie ~250 parameters, in fact I have another 250 params for the case ascertainment ratio which also varies in time in a similar manner, so 500 in all). The R time series is vaguely similar to the BSU plots though they seem to be using weekly piecewise-constant R values meaning 20-30 parameters. I suspect they are using a more common MCMC approach which is very general and widespread but less efficient and can't handle so many parameters as my method. I tried that initially and also got stuck at the level of weekly R values. The iterative Kalman smoother is something I developed 15 years back in another context, it's rather fortuitous that it happens to work so well here.
I don't think the difference in our results is really due to number of parameters though. This sort of thing has been literally my research career for the past several decades, and it just seems they aren't quite as good at it as I am. It was obvious at a glance that their previous forecast was very high and their new one is a radical correction. I find it concerning that I'm so easily able to improve on the forecasts of people who are advising the government. Like you, I'm only doing this as a hobby in a bit of spare time.
This is an example of what I produce on a daily basis:
https://twitter.com/jamesannan/status/1318983350875541504?s=20
I'm not going to pretend to understand the above, but I do know statistics are only as good as the input data. Having experienced the 'testing' facilities we're paying billions to SERCO to provide, I hope you're allowing for significant levels of false negatives if the calculations you're using require the use of both positive and negative test results!
I suspect they are using a more common MCMC approach which is very general and widespread but less efficient and can’t handle so many parameters as my method.
They are. With relatively strong assumptions about parameter spaces. I like your approach of case ascertainment and R as relatively free parameters (but R probably has some time for change too rather than falling off a cliff as the Govt would wish). The model can then try and infer local (in time) values of R and ascertainment. Both R and testing (ascertainment) are nuisance parameters in the model. I gave up on cases a long time ago. Now they basically tell you which areas have a university!
On a technical point, people have an inconvenience of being integers, so when numbers get low, distribution assumptions become important - hence Poisson or negative binomial distributions of some form are needed - you see this at the regional level for deaths in particular. The SEIR models being used are individual-based in that they count in integers and transition them from state to state after some time dependent on a distribution - normally Weibull rather than exponential (as per normal ODEs). Then one needs to run 10,000 runs to estimate prediction intervals.
The statistical method for local regression is spline fitting. That's also been done by PHE group on their survey data. To be perfectly honest, 30 years of modelling (5 doing epidemiology, and 20 doing non-linear mixed effects) has left me more disillusioned with mechanistic models and more enamored with statistics. It's not Physics and one should not pretend it is.
It’s not Physics and one should not pretend it is.
Positivism was fashionable in the 60s in fields such as social sciences, economics etc. It was thought that with enough parameters human behaviour could be reliably predicted as you say mechanistically and deterministically. Everyone was looking for iron laws. Theoretical foundations for this can be found with Spencer, Comte, etc. It's generally been abandoned for more modest modelling using statistical methods with acknowledged limited generalisability. Anything involving human behaviour seems to resit being understood like physics.
Two PhDs having a difference of opinion about statistical analysis and forecasting - that must be the pure essence of this forum.
They’re both wrong. In a while we’ll see who was the least wrong...
weeks of medical warning of a 2nd rise, to which our fat useless PM says " Lets put the schools back and colleges/unis too.
Surprise surprise were now in a worse state than March.
SO.
Knowing of a 2nd rise, yet still sending kids back it appears they want the virus to spread slowly. It appears given that dumbo move they want the virus to infect everyone and whomever survives survives.
But they need to do it slowly so as not to overwhelm the services.
Tell me Im wrong. Logic is something us Aspies have and this entire mess stinks
@TheCaptain - can having so many parameters in your model risk misspecification/bias of some kind? What's the probability of your model being correct by chance? What does having 200-500 parameters achieve?
I need a day of googling to properly digest both yours and TiReds posts, so be patient with me - I'm essentially an idiot undergrad when it comes to stats.
several decades
You a 90 year old quant? 😀
The fact is, they are set to squander the natural fire break opportunity that half-term gives us. The schools are out already, so why not make it a bit longer and shut everything else for a couple of weeks to try to minimise mixing?
All they are offering is a slow grind into Tier 3 for everyone, where they will remain well past Christmas.
The tragedy is that following the SAGE advice - remote learning for unis in term 1, firebreak lockdown - would most likely be far less economically damaging than this.
That's me too. A little stats knowledge from university but not a lot.
With so many specified parameters in a model, I'd be concerned about overfitting.
That's my 2-pence intelligent comment. 🙂
All they are offering is a slow grind into Tier 3 for everyone, where they will remain well past Christmas.
I’m afraid so. Grim. I’d at least have some respect for them if they were preparing the public for this… it’s going to get messy when people paying less attention work out what they are being walked into.
The tragedy is that following the SAGE advice – remote learning for unis in term 1, firebreak lockdown – would most likely be far less economically damaging than this.
This. This. This. Too late now though. The damage is coming, with very limited help for those hit hardest by this policy decision.
They’re both wrong. In a while we’ll see who was the least wrong…
The truth is, there will probably be an intervention before the end of the prediction interval. So I hope I am wrong! I think the government were holding out to get to half-term, then have some form of harder lockdown when the schools were out as a homage to March. Things seem to have grown a little faster and the North is running away. The South will follow but will likely feel the earlier effects of intervention.
If you want a rule of thumb, the epidemic declined at 3%/day and is now increasing at 5%/day. So you need about 5 days of lockdown to win 3 days of growth. It was 21 days of lockdown to win 3 days in March, so be thankful for something.
That’s me too. A little stats knowledge from university but not a lot.
With so many specified parameters in a model, I’d be concerned about overfitting.
That’s my 2-pence intelligent comment.
Hah! I'm still trying to learn, which is why I'm asking what are probably fairly thick/idiot questions, it's just life got a bit in the way of converting from the biosciences to stats. 🙁
I do like a good argument as well though - that and I think stats is rock and roll - which get's me horrified/weird/disturbed looks even amongst biologists and chemists that look like they've been chained up in the basement of some dark establishment building for the past 30 years.
Knowing of a 2nd rise, yet still sending kids back it appears they want the virus to spread slowly. It appears given that dumbo move they want the virus to infect everyone and whomever survives survives.
But they need to do it slowly so as not to overwhelm the services.
That's always been the case. The only alterative is eradication that I don't believe they've even suggested they'd pursue that. The hope has always been for a quick vaccine or improved medical treatment to maximise NHS capacity. Our government is at best incompetent and at worst corrupt so we'll end up with massive short term deaths from covid, and longer term problems from the economic and social damage.
I personally fundamentally disagree with lockdowns but don't deny that a comprehensive (much harsher than we've had before) one of 2-3 weeks would reduce the number of deaths over the next few months. Long term would be a different matter but that could to a degree be mitigated with the right support.