It's really taken sombody all this time to notice that photocopiers distort characters, especially at small sizes, causing certain figures and letters to look like different ones?
I was aware of that thirty years ago... 🙄
It's more than distortion, it seems that it's actually doing OCR on the image and then reconstituting it.
It's more than distortion, it seems that it's actually doing OCR on the image and then reconstituting it.
They're all scanners and printers now, with a processor in between, hence data gets corrupted in the lossy process between the two ends.
[i]When is a photocopy not a photocopy?[/i]
When it's taken on a iBum chair?
[img]  [/img]
[/img]
Welcome to the digital world.
The only people surprised by this are really failing to understand exactly what is going on inside a scanner- it's not OCR'ing and then magically substituting characters, it's simply a compression artefact.
Granted it's rather an unfortunate one- one that should probably be avoided by Xerox choosing an appropriate amount of compression in the software!
Numbers were randomly being altered, with 6 and 8 proving especially susceptible.
That's not randomly then is it.
theroadwarrior - MemberWelcome to the digital world.
The only people surprised by this are really failing to understand exactly what is going on inside a scanner- it's not OCR'ing and then magically substituting characters, it's simply a compression artefact.
Granted it's rather an unfortunate one- one that should probably be avoided by Xerox choosing an appropriate amount of compression in the software!
It's a strange artifact though, I reckon they are doing pattern matching, the scanner effectively learning the font as it goes through the document, replacing subsequent uses of the same(!) letters with just a pointer back to the first instance.
So in a way, it's closer to deduping rather than a traditional lossy compression algorithm like JPG. Very clever, but obviously needs more tuning!
The only people surprised by this are really failing to understand exactly what is going on inside a scanner- it's not OCR'ing and then magically substituting characters, it's simply a compression artefact.
No that's not right, the compression format involved actually does OCR to find characters, so if the OCR has an error between similar characters like 6 and 8, then a completely wrong character gets put in. It is a symbol based compression format. Nothing like what is traditionally thought of as a compression artifact.
http://en.wikipedia.org/wiki/JBIG2
Why it is worse than blurred figures and traditional compression artefacts is that an error is not obviously blurred and hard to read, it comes out as a perfectly rendered but wrong symbol.
[img] 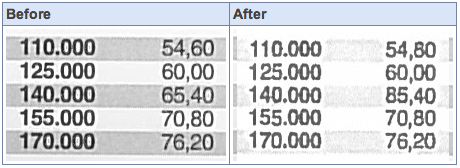 [/img]
[/img]
Yup, see the 3rd line - that's not a blurry 6, that's an 8. That's not a traditional compression artifact, it's an OCR error.
No good for photocopying bank notes then...
I've never had much luck with my fake £6 notes anyway...
My god, what if someone photocopies an Excel spreadsheet......!
[img]  [/img]
[/img]
My god, what if someone photocopies an Excel spreadsheet......!
Don't be silly, you can never get the laptop screen to sit flat enough on the copier.
I've never had much luck with my fake £6 notes anyway...
you'd do better to copy them into £8 notes 😉