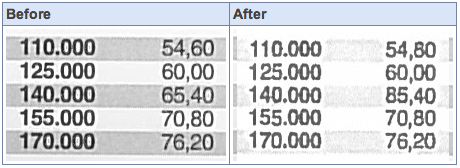
Welcome to the digital world.
The only people surprised by this are really failing to understand exactly what is going on inside a scanner- it’s not OCR’ing and then magically substituting characters, it’s simply a compression artefact.
Granted it’s rather an unfortunate one- one that should probably be avoided by Xerox choosing an appropriate amount of compression in the software!
It’s a strange artifact though, I reckon they are doing pattern matching, the scanner effectively learning the font as it goes through the document, replacing subsequent uses of the same(!) letters with just a pointer back to the first instance.
So in a way, it’s closer to deduping rather than a traditional lossy compression algorithm like JPG. Very clever, but obviously needs more tuning!